How to generate A.I. images with Stable Diffusion on your MacBook M1/M2 in less than 30 seconds for FREE
Run Stable Diffusion on your M1 Mac’s GPU
 |
What is Stable Diffusion?
A text-to-image algorithm using deep learning called Stable Diffusion was launched by the firm StabilityAI in 2022. Although it may be used for various tasks including inpainting, outpainting, and creating image-to-image translations directed by text prompts, its primary usage is to produce detailed visuals conditioned on text descriptions.
Researchers at LMU Munich created Stable Diffusion, a type of latent diffusion model and generative neural network. With assistance from EleutherAI and LAION, Stability AI created it with the help of LMU, Runway, and Stability. As of September 2022, Stability AI is in discussions to raise money at a valuation of up to one billion dollars.
The code and model weights for Stable Diffusion have been made available to the public, and it can function on the majority of consumer hardware with a low-end GPU. This was a change from earlier proprietary text-to-image models that were only accessible through cloud services, including DALL-E and Midjourney.
Stable Diffusion is open source, so anyone can run and modify it. That's what has caused the abundance of creations over the past week.
You can run Stable Diffusion in the cloud on Replicate, but it's also possible to run it locally. As well as generating predictions, you can hack on it, modify it, and build new things. Getting it working on an M1 Mac's GPU is a little fiddly, so I've created this guide to show you how to do it.
Prerequisites
- A Mac with an M1 or M2 chip.
- 16GB RAM or more. 8GB of RAM works, but it is extremely slow.
- macOS 12.3 or higher.
- Upgrade MacOS to the latest version (top left 🍎 -> About This Mac -> Software Update)
- Open Terminal app
- Install Homebrew from brew.sh
Set up Python
You need Python 3.10 to run Stable Diffusion. Run python -V to see what Python version you have installed:
$ python3 -V !11338
Python 3.10.6
If it's 3.10 or above, like here, you're good to go! Skip on over to the next step.
Otherwise, you'll need to install Python 3.10. The easiest way to do that is with Homebrew. First, install Homebrew if you haven't already.
Then, install the latest version of Python:
brew update
brew install python
Now if you run python3 -V you should have 3.10 or above. You might need to reopen your console to make it work.
Type the commands below in terminal and press Enter:
Run this to clone the fork of Stable Diffusion:
git clone -b apple-silicon-mps-support https://github.com/bfirsh/stable-diffusion.git
cd stable-diffusion
mkdir -p models/ldm/stable-diffusion-v1/
Then, set up a virtualenv to install the dependencies:
python3 -m pip install virtualenv
python3 -m virtualenv venv
Activate the virtualenv:
source venv/bin/activate(You'll need to run this command again any time you want to run Stable Diffusion.)
Then, install the dependencies:
pip install -r requirements.txt
If you're seeing errors like Failed building wheel for onnx you might need to install these packages:
brew install Cmake protobuf rust
Download the weights:
Run it!
Now, you can run Stable Diffusion:
python scripts/txt2img.py \
--prompt "a red juicy apple floating in outer space, like a planet" \
--n_samples 1 --n_iter 1 --plms
Your output's in outputs/txt2img-samples/. That's it.

If it works, the image is saved under /outputs/txt2img-samples
Make sure you upgraded MacOS to the latest version (double check). And make sure you actually have an M1/M2 MacBook (those are the latest MacBooks)
If you want to adjust the detail (and speed of generating it) here's some tips to use --ddim_steps param
You can type as CLI param:
--ddim_steps 1
It defaults to 50 which takes 30 seconds on M1 16" for me
These pics are:
--ddim_steps 1 (0.6 secs)
--ddim_steps 10 (6 secs)
--ddim_steps 50 (30secs)
--ddim_steps 100 (1min)
Nice to iterate fast with low steps
Random text prompts collection:
cinematic photo, highly detailed, cinematic lighting, ultra-detailed, ultrarealistic, photorealism, 8k, octane render,
cyberpunk lights, Hyper Detail, 8K, HD, Octane Rendering, Unreal Engine, V-Ray, full hd,
cyberpunk, abstract, full hd render + 3d octane render +4k UHD + immense detail + dramatic lighting + well lit + black, purple, blue, pink, cerulean, teal, metallic colours, + fine details + octane render + 8k,
ultra photoreal , photographic, concept art, cinematic lighting, cinematic composition, rule of thirds , mysterious, eerie, cinematic lighting, ultra-detailed, ultrarealistic, photorealism, 8k, octane render,
If you quit the Terminal or reboot, you get kicked out of the virtualenv, to get back in type:
source venv/bin/activate
And run you rprompt
python scripts/txt2img.py --n_samples 1 --n_iter 1 --plms --prompt "your text here"
And there's an NSFW filter, but you can disable it easily by editing some files:
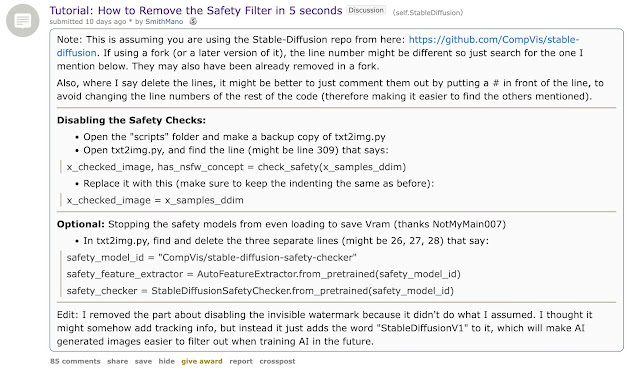
How to control the resolution/size of the image?
Can't really. Pump it into an upscaler eg. Click HERE.
So instead of ignoring or worrying about AI, I think creators should embrace it as a tool to help them create better content.
Ignoring AI is like sticking to Microsoft Paint as a digital artist when Photoshop is available. At the minimum, you should explore the following:
1. Try Stable Diffusion’s Dream Studio and use Lexica for prompt ideas. If you run out of free credits, you can install the model locally (see this Reddit post).
2. Sign up for OpenAI’s GPT-3 (text) and check their prompt examples. You might have to wait on a waitlist for access.
Of course, AI models are always learning and improving. One thing is clear:
Humans have always been defined by our tools, and AI tools are simply too good for creators to ignore.
If you like this blog, why not share it?
credit: Levelsio & Ben Firshman

Comments
Post a Comment